

School of Science and Technology 科技學院
Computing Programmes 電腦學系
| Programme | Bachelor of Computing with Honours in Internet Technology |
| Supervisor | Dr. Andrew Lui |
| Areas | Algorithms |
| Year of Completion | 2021 |
| Award | First Runner-up of IEEE (HK) Computational Intelligence Chapter 18th FYP Competition |
The aim of the project is to use observational data to build a deep machine learning model to model the relation between the accident proneness and road network structure design, road installations, and road local properties. In conclusion, this model provides a basis for improving the conditions of traffic facilities and enhancing traffic safety.
A. Design of the model

Figure 1: Architecture of the deep machine learning model
There are mainly three parts of the model, which includes input parameters, the deep machine learning model as well as the output target. The methodologies of each component are shown as follows.
B. Data CollectionAfter choosing the desirable area, we collected the data from OpenStreetMap about the map structure in this specific area. There are two main types of data provided by OpenStreetMap. The first type is node data, which describes the features and information of the concatenate point between roads. For example, the data contains the street count and the geographical information of the node. Another type of data is edge data, which describes the features and information of the road on the map. For example, the data contains the start node OSMID and end node OSMID that form the edge, highway type of the edge, edge length, and so forth.
C. Data Preprocessing and IntegrationAfter collecting the information from OpenStreetMap, we conducted feature selection. We have selected the features related to accident proneness empirically, including length, maximum speed, oneway, highway, bridge, lanes, ref, junction, access, service, and tunnel. These are the keys in the OpenStreetMap dataset.
As shown in Figure 1, we divided the input parameters in three types, which contains road network structure, road installations and road local properties. We could make good use of the obtained features and utilize them. For the road network structure, it will be discussed in the next section. In this section, we discuss the transformation of features from above to entity embedding, which includes road installations and road local properties. For road installations, we chose the features of oneway, highway, bridge, lanes, ref, junction, access, service, and tunnel. If it is a categorical feature, it will be one-hot encoded. Otherwise, the numerical value will be retained.
Other than the input features, we should also consider the preparation of accident mapping in the dataset.
In fact, the raw data crawled from the news is dirty, which means the content is in various data formats, and it cannot be used before data cleaning and filtering. Data filtering and data integration are benefits to help extract meaningful traffic accident data from the raw data. First, we retrieved the name list of all roads from the OpenStreetMap dataset (it only contains the road information of our desired area) and removed all duplicated names inside the dataset. Then, we filtered the traffic accident dataset (it contains all accident data in Hong Kong) with the name list of all roads so that the accident data outside our desired area can be removed. After that, we defined some filtering keywords so that the accidents other than traffic accidents (e.g. pipe burst) can be removed from the accident dataset. This accident dataset was cleaned and ready to integrate with the OpenStreetMap dataset as well as performing accident data mapping.
For the output target, we defined the accident prone as 0 or 1 for whether an accident has happened. Since there is no official and rich dataset for us to do prediction, and we are not sure the scale and exact location of the data crawled from news. Therefore, mapping 0 or 1 for the involved area for whether an accident happened is the most feasible way, and we call it hot-zone mapping.
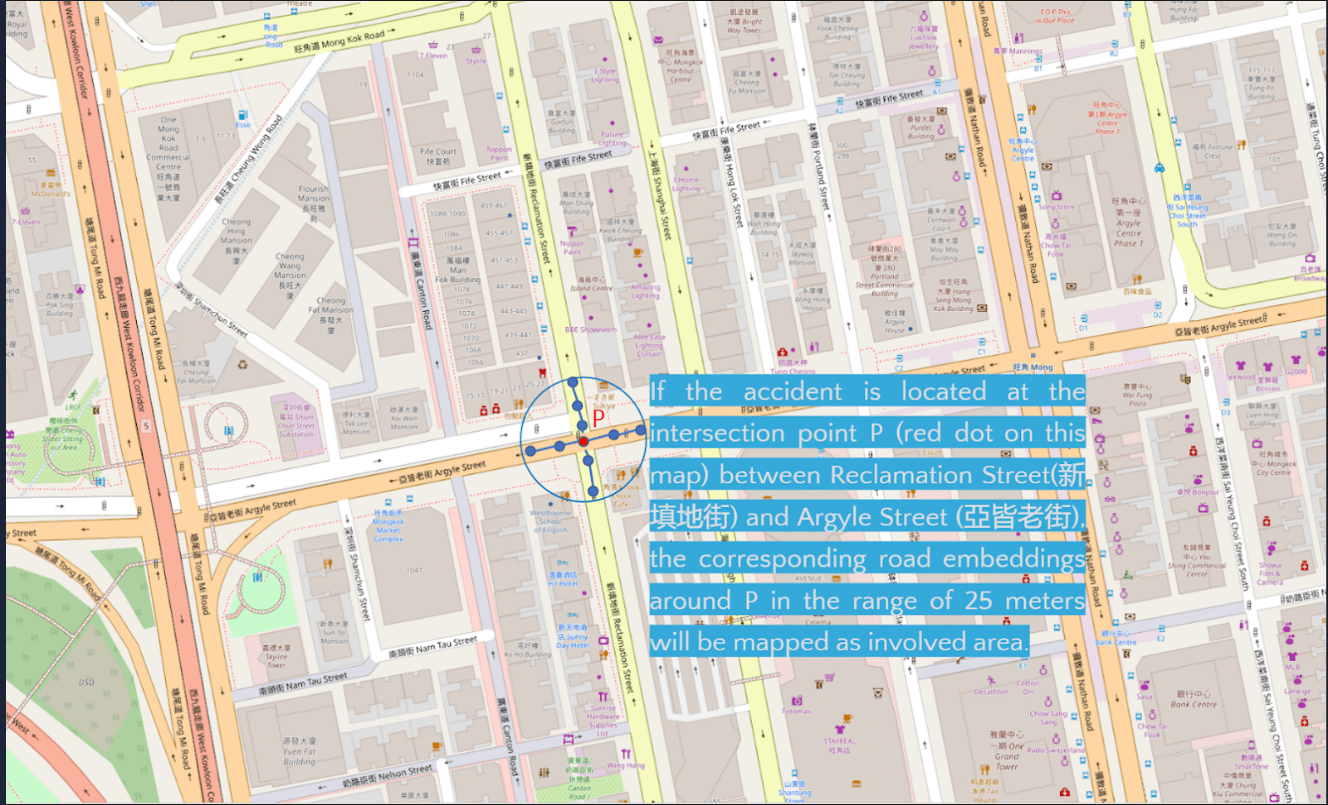
Figure 2: Mapping accident hot-zone with intersection
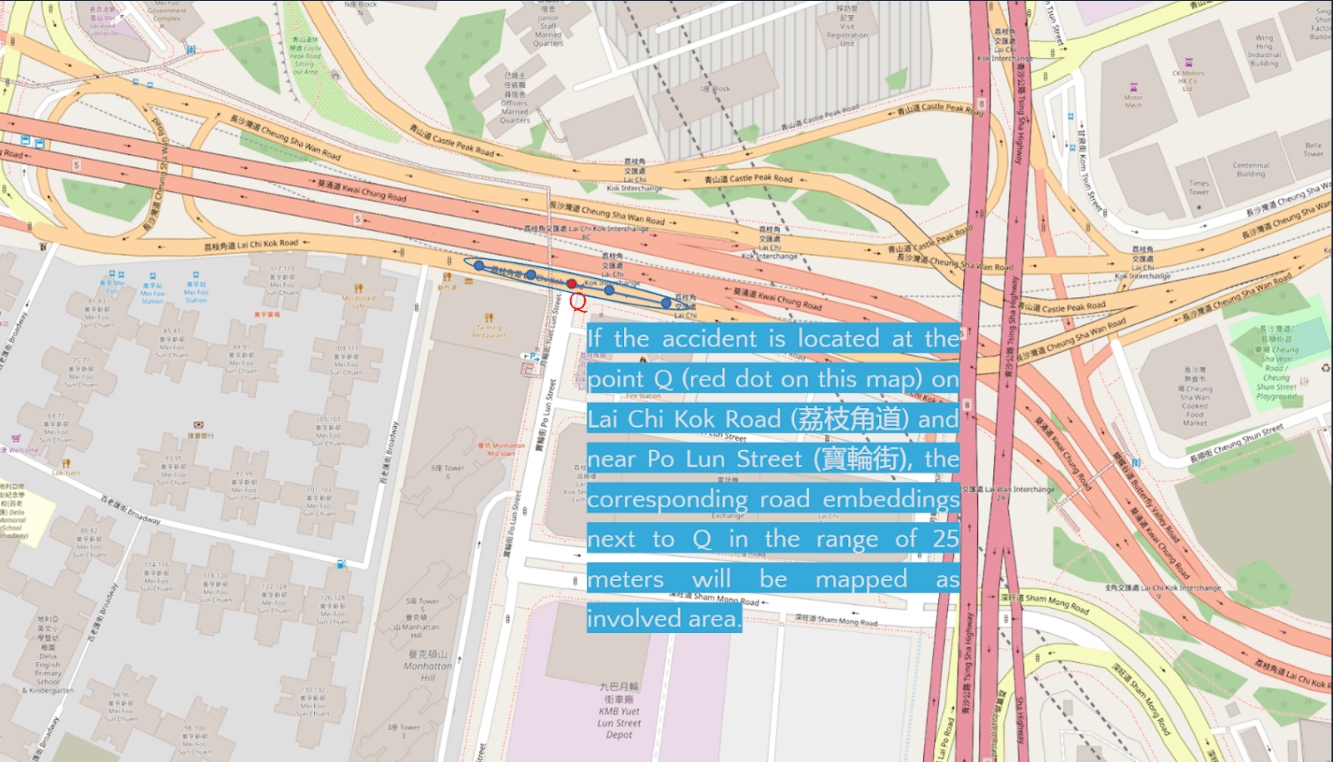
Figure 3: Mapping accident hot-zone with the point on a road
Our idea is to use the road network structure with various weights as the input features for training the model to predict traffic accidents. Node2vec is then our network embedding method of choice since it relies solely on network structure while optimizing for the core property of neighborhood preservation in the embedding space, a property shared by most network embedding methods. So that, node2vec is applicable when little or no attribute information is available in the road network, as is the case in our data set.
Extending the dataset can help to enrich the input features of the model on predicting traffic accidents. After decision-making about the weight used in the Node2vec model, we extract the data from the integrated dataset of the OpenStreetMap. Then transform the corresponding data into the correct data format for building the Node2vec node embedding models.
Since our purpose is to use the edges as roads in the road network structure, we have to do one more step to make the node embedding representation model to the edge embedding representation model. We use the Hadamard transform to combine the two node-embedding models directly because both node-embedding models have the same matrix size. So, there is no need to do an extra process to transform the matrix. During the Hadamard transform process, we use the addition between the two matrices rather than doing multiplication. Because the matrix may contain a zero number, which may cause the non-zero value in the matrix to be a zero number, so we decide to use addition instead of multiplication to prevent this issue.
E. Dense Layer Classification ModellingKeras is a deep learning model framework, it is extendable and easy to use. It may be very difficult to create a CNN model under TensorFlow but it is easy to create a CNN model under keras. Different from the tensorflow provided model,e.g: the logistic model, the user can adjust the number of layers of neurons according to the complexity of the real problem. Moreover, keras model allows multiple input layers which can make the model distinguish different types of data and enhance its performance. Keras are usually used in multiple classifications.
First, we need to extract the data to be our features,since the dataset is already processed , we just need to extract data from csv and node2vec model direct.Then we can design the structure of the keras model according to number of features, then we need to try different epochs and number of input layers and units, and optimizer to get a relatively good performance of the model. If there are too many features, then the number of dense layers and neurons should be more. In this project, we evaluate the model by f1 score. For data processing, it is better to apply one-hot encoding to all categorical data because some machine learning models don’t accept strings as input.
Performance Evaluation
Because the dataset is unbalanced, positive sample is about 62%, negative sample is about 38%. Therefore, we cannot mainly use accuracy to evaluate our model. We want to cover both recall and precision, since we think that the prediction of correct target is important as the predicted value cover the real life sample. Because of an unbalanced dataset, we choose micro f1 score instead of macro f1 score. We evaluate our deep learning model by testing data. The micro f1 score is 0.8642895156998404 and the loss is 0.3413464426994324. In ROC curve, the true positive rate is higher than false positive rate. Therefore, our trained model can predict whether the road structure/road installation will cause accident or not successfully.

Figure 4: Classification Report

Figure 6: Confusion Matrix
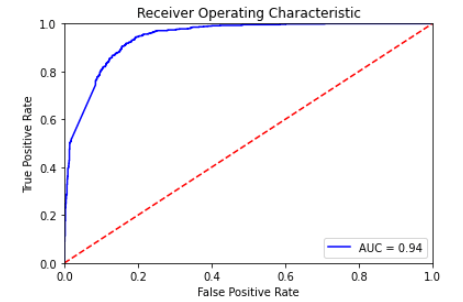
Figure 5: ROC Curve
In conclusion, we could address the big research question which is “How could we predict the accident proneness of a road segment or location based on road network structure, road installations, and road local properties?”
Our experiments and evaluation indicate that road network structure, road installations, and road local properties could predict accident proneness. The deep learning graph embedding algorithms (Node2vec) is an effective approach to learn the road network structure by the model.
We designed an input model including road structure embedding and road entity embedding as the input parameters. On top of input parameters, we designed the hot-zone mapping approach to label the dataset with whether an accident existed or not. Through training the deep machine learning model (dense layers) and conducting several experiments, we found that road network structure, road installations, and road local properties could predict accident proneness in our experiments.
The empirically most important features are the Node2vec embedded model with the best travel time of the road, the Node2vec embedded model with the length of the road, the bridge-type describes the road, the highway-type describes the road, the junction-type of the road, the number of lanes in the road, and the slope of the road. In our experiment, using the features together performs better than just using one single feature. We then experiment with the effectiveness of the features. We found that most of our features are effective, indicating that we have chosen effective features in the process of feature selection.
We attempted to increase the accuracy and decrease the loss of our deep machine learning model to avoid overfitting so that the model could be more generalized.
Besides, as stated in chapter 5, there are several potential improvements for the model as well as some possible adaptations to other solutions with similar nature. Therefore, it is beneficial to find the key factors in road design contributing to accidents in different situations. Once we understand the key factors of traffic accidents, we could take valuable measures to improve traffic safety with traffic facilities.
So far, we have tested the importance of the features.
However, there are other ways to improve the model but not yet implemented.
First, there may be some more useful features that we have not selected. It may be
Therefore, more potential effective features can be further developed.
Second, most of our features are considered with just one approach to add in the deep machine learning model as an input parameter. Most of them have not been evaluated which way to add that feature is the best. We have tried to add the bending angle to the node2vec model, but because the weight of Node2vec cannot be negative, the bending angle can only be placed in the entity embedding as a part of road local properties. Bending angle is one of our features that tried to use more than one method to add it in the model. For most of the other features such as slope, we have not yet attempted to test the best way to add it in the model. How could we make the most effective use of the feature information? For the time being, we suggested another way to alter the way of adding the slope as input parameter. One feasible way is by taking the logarithm function for the input values of the slope and observing the result. Given that the slope features are numeric numbers, the numbers may not be the linear relationship. For example, -1 to -2 may not have the same effect as -2 to -3. An experiment could be conducted so that the effect of lower magnitude of the slope could be magnified while the effect of higher magnitude of the slope could be minified by taking the logarithm function for the input values. We then could evaluate the result (e.g. accuracy) after the experiment.
Apart from the possible improvements of the model, we expect that our findings generalize to other solutions with similar nature. Through altering the parts of input parameters, model, and the output layer, the new solution could be adapted based on our existing solution. For example, if one stakeholder would like to test the relation between a long downhill road and accident proneness, we would modify the experiment design such as adding a new one-hot encoded feature indicating whether that node or edge is a long downhill road.

Jonathan handles all external affairs include business development, patents write up and public relations. He is frequently interviewed by media and is considered a pioneer in 3D printing products.

After graduating from OUHK, Krutz obtained an M.Sc. in Engineering Management from CityU. He is now completing his second master degree, M.Sc. in Biomedical Engineering, at CUHK. Krutz has a wide range of working experience. He has been with Siemens, VTech, and PCCW.

Hugo Leung Wai-yin, who graduated from his four-year programme in 2015, won the Best Paper Award for his ‘intelligent pill-dispenser’ design at the Institute of Electrical and Electronics Engineering’s International Conference on Consumer Electronics – China 2015.
The pill-dispenser alerts patients via sound and LED flashes to pre-set dosage and time intervals. Unlike units currently on the market, Hugo’s design connects to any mobile phone globally. In explaining how it works, he said: ‘There are three layers in the portable pillbox. The lowest level is a controller with various devices which can be connected to mobile phones in remote locations. Patients are alerted by a sound alarm and flashes. Should they fail to follow their prescribed regime, data can be sent via SMS to relatives and friends for follow up.’ The pill-dispenser has four medicine slots, plus a back-up with a LED alert, topped by a 500ml water bottle. It took Hugo three months of research and coding to complete his design, but he feels it was worth all his time and effort.
Hugo’s public examination results were disappointing and he was at a loss about his future before enrolling at the OUHK, which he now realizes was a major turning point in his life. He is grateful for the OUHK’s learning environment, its industry links and the positive guidance and encouragement from his teachers. The University is now exploring the commercial potential of his design with a pharmaceutical company. He hopes that this will benefit the elderly and chronically ill, as well as the society at large.
Soon after completing his studies, Hugo joined an automation technology company as an assistant engineer. He is responsible for the design and development of automation devices. The target is to minimize human labor and increase the quality of products. He is developing products which are used in various sections, including healthcare, manufacturing and consumer electronics.
| Course Code | Title | Credits | |
|---|---|---|---|
| COMP S321F | Advanced Database and Data Warehousing | 5 | |
| COMP S333F | Advanced Programming and AI Algorithms | 5 | |
| COMP S351F | Software Project Management | 5 | |
| COMP S362F | Concurrent and Network Programming | 5 | |
| COMP S363F | Distributed Systems and Parallel Computing | 5 | |
| COMP S382F | Data Mining and Analytics | 5 | |
| COMP S390F | Creative Programming for Games | 5 | |
| COMP S492F | Machine Learning | 5 | |
| ELEC S305F | Computer Networking | 5 | |
| ELEC S348F | IOT Security | 5 | |
| ELEC S371F | Digital Forensics | 5 | |
| ELEC S431F | Blockchain Technologies | 5 | |
| ELEC S425F | Computer and Network Security | 5 |
| Course Code | Title | Credits | |
|---|---|---|---|
| ELEC S201F | Basic Electronics | 5 | |
| IT S290F | Human Computer Interaction & User Experience Design | 5 | |
| STAT S251F | Statistical Data Analysis | 5 |
| Course Code | Title | Credits | |
|---|---|---|---|
| COMPS333F | Advanced Programming and AI Algorithms | 5 | |
| COMPS362F | Concurrent and Network Programming | 5 | |
| COMPS363F | Distributed Systems and Parallel Computing | 5 | |
| COMPS380F | Web Applications: Design and Development | 5 | |
| COMPS381F | Server-side Technologies and Cloud Computing | 5 | |
| COMPS382F | Data Mining and Analytics | 5 | |
| COMPS390F | Creative Programming for Games | 5 | |
| COMPS413F | Application Design and Development for Mobile Devices | 5 | |
| COMPS492F | Machine Learning | 5 | |
| ELECS305F | Computer Networking | 5 | |
| ELECS363F | Advanced Computer Design | 5 | |
| ELECS425F | Computer and Network Security | 5 |





